
ここ最近、恐ろしいほどにAI技術が急速に発展してきています。
Stable Diffusion(ステーブル・ディフュージョン)は、2022年8月に公開されたAI画像生成モデルで、ユーザーが入力したテキストに基づいて高品質な画像を生成します。
また、OpenAI社が2022年11月に対話型の生成AIサービスの「ChatGPT」(LLM)を開発・リリースしました。
LLM(大規模言語モデル)は、膨大なテキストデータと深層学習を用いて構築されたAIモデルです。自然言語処理に特化しており、テキスト生成や質問応答など、幅広いタスクに活用されています。
一般的にLLM(大規模言語モデル)は扱うデータ容量が膨大なため、データセンタークラスのPC設備が必要です。
現在ではAI技術をクラウドでサービス提供するビジネスが急増しており、世界各地でAI用のデータセンターが建設されています。
コンシューマ向けのグラフィックカードや、64GB未満のPCメモリではLLM(大規模言語モデル)を動かすることすらできません。
AI用に使用されるメモリはHBM(High Bandwidth Memory)といわれ、超高速かつ大容量のデータ転送を実現しています。
HBM(High Bandwidth Memory)はメモリを製造するDRAMメーカーにとって高収益が期待できる製品のため、製造ラインのほとんどをHBMに振り向けています。
また、LLM(大規模言語モデル)を取り扱う際にデータ容量が膨大になるため、SSDでは容量が足りずHDD(ハードディスク)の需要がデータセンターで高まっています。
そのあおりを受けて、個人用PCパーツのメモリやHDDの生産が圧迫され世界中で品薄になっている状況です。

LLM(大規模言語モデル)はサーバークラスのPCが必要で一般的なPCでは使用できないと思われていましたが、2025年8月にGPT-OSS-120BやGPT-OSS-20Bが発表・リリースされ、比較的小さいAIモデルのLLM(大規模言語モデル)ならローカルPCでも使用できるようになりました。
ローカルLLM(大規模言語モデル)は、クラウドを介さずにローカル環境で動作するAIモデルです。これにより、プライバシー保護やオフライン利用が可能となり、API利用料の削減やカスタマイズ性の向上といった利点があります。
ミニPCのパーツ構成
GPT-OSS-120B モデルは、単一の80GB GPU で効率的に稼働しながら、コア推論ベンチマークで OpenAI o4-mini とほぼ同等の結果を達成します。
「単一の80GB GPU 」ってなんのこっちゃと思われるかもしれませんが、これが非常にやっかいな条件なんです。
AI技術を運用するにはGPUなどの高性能なコンピューティングユニットと、超高速なメモリが必要です。
特に一般的なPCメモリはAI分野では「低速」の部類に分類され、サーバーで使用されるHBM(High Bandwidth Memory)やグラフィックカードに搭載されているVRAMは「高速」なメモリに分類されます。
超高速なメモリは一般の方にとっては用意することが難しいパーツです。
現在市場価格で約40万円以上する「NVIDIA RTX5090」ですら32GB(VRAM)しかありません。
「単一の80GB GPU 」の条件を満たすGPU(グラフィックカード)は価格150万円の「NVIDIA RTX PRO 6000 96GB」しかありません。AIは恐ろしい世界ですね!
高速なVRAM(グラフィックメモリ)を豊富に搭載したGPUは、一部のブルジョワやAI企業しか金額的に手が出ません。
そこで次善の策として、Appleが開発した「ユニファイドメモリ(unified memory・統合メモリ)」や、ミニPCに採用されているLPDDR5などはVRAMには敵わないまでも従来のPCメモリよりデータ転送速度が数倍高速なため、AIモデルを展開するためには非常に有用となりました。
しかし、512GBの「ユニファイドメモリ」を搭載した「Mac Studio」は約160万円しますし、128GBのLPDDR5を搭載した「Minisforum MS-S1 MAX」も約40万円の価格です。
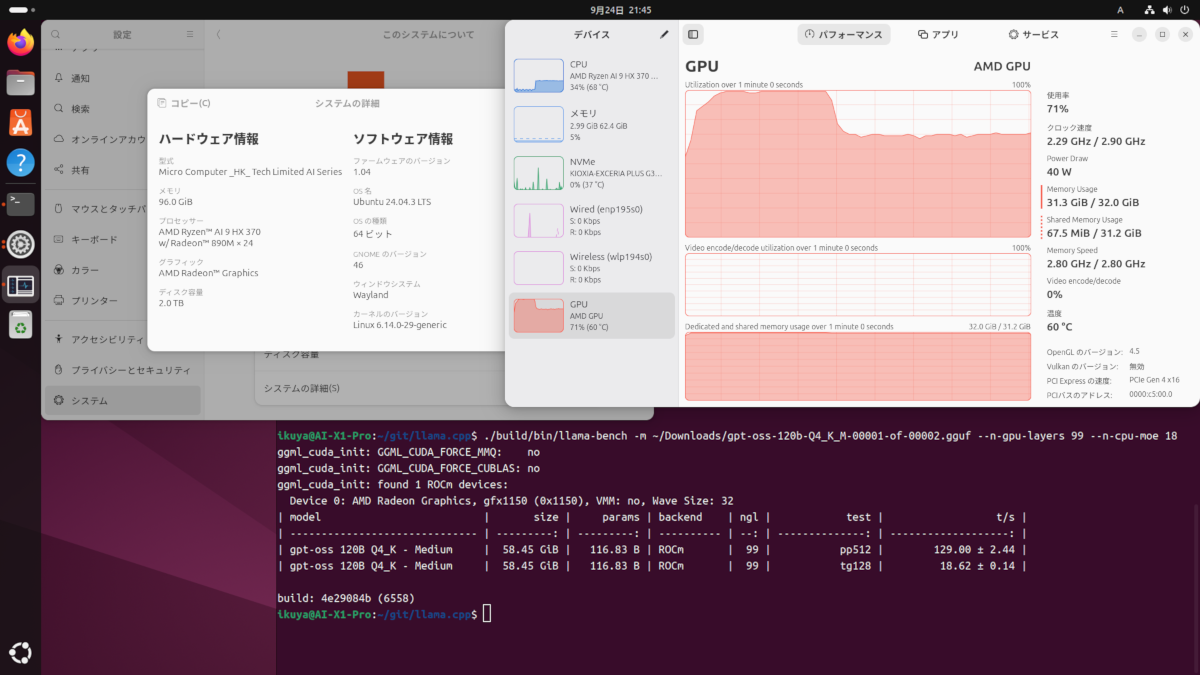
ワンランク下のAPU「Ryzen AI 9 HX 370」搭載ミニPCですらメモリ96GB搭載の製品は20万円以上費用が掛かります。
↓こちらはPC WATCHさんの記事です↓
2025年10月に、128GBのLPDDR5Xユニファイドシステムメモリを搭載し、最大2000億パラメータのAIモデルの推論処理や、最大700億パラメータのモデルのファインチューニングが可能な「NVIDIA DGX Spark」が発売されましたが、こちらも価格が約70万円します。
私たち庶民が手にすることができるローカルLLM(大規模言語モデル)環境は、一般的なPCに128GBなどの大容量なPCメモリを増設して「GPT-OSS-120B」を動かすことが精一杯です。
幸い私は、意味不明にもミニPCのメモリを前もって128GBへ増設していたため、今回「GPT-OSS-120B」を動かすチャレンジをしてみました!!
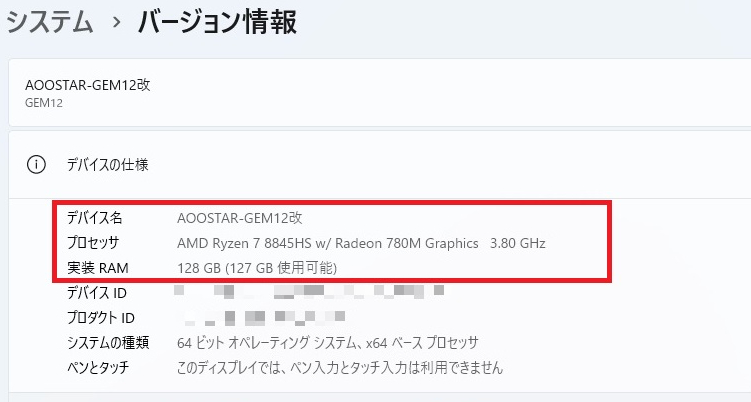
今回使用するミニPCは「Ryzen AI 9 HX 370」や「Ryzen Al Max+ 395」でもない、ただの「Ryzen7 8845HS」搭載ミニPCです。


私のミニPC「AOOSTAR GEM12」は現在このようなPCパーツ構成になっています。
| PCパーツ種類 | 構成PCパーツ名 |
| CPU | AMD Ryzen 7 8845HS |
| グラフィック | AMD Radeon 780M(APU内蔵) |
| グラフィック | NVIDIA GeForce RTX4060ti 16GB(OcuLink接続) |
| メモリ | Crucial 128GB Kit(2x64GB) DDR5-5600 SODIMM CT2K64G56C46S5 |
| SSD(OS用) | Crucial T500 2TB Gen4 NVMe M.2 CT2000T500SSD8JP |
| SSD | ORICO IG740PRO 4TB PCIe 4.0 M.2 NVMe 2280 |
| RAMdisk | Crucial 128GB Kitより16GB割り当て(一時ファイル展開用) |
| wifi | MT7922 Wifi6E+BT5.2 |
| OS | Windows11 pro |
「GPT-OSS-120B」を運用する環境に掛かった費用は、上記ミニPC構成から最低限の見積もりを行ったところ、「AOOSTAR GEM12:7万円」+「メモリ128GB:4万円」+「RTX4060ti 16GB:6万円」+「Minisforum DEG1:1万1千円」の約18万円でした。
「Ryzen APU」のみを使用するローカルLLMは、「TheRockのビルド」や「llama.cppのビルド」など各種プログラムの知識が無いとAI導入の敷居が高いため、今回は「RTX4060ti 16GB+Minisforum DEG1」をOculinkで外部接続することにより手軽にCUDA環境を構築しました。
↓↓「Minisforum DEG1を用いたOculink接続の外部GPU導入」はこちらの記事をご参照ください↓↓

CUDA環境の何が良いかというと、「CUDA Toolkit」+「Python」+「PyTorch」を導入することで簡単に「LM Studio」などで「GPT-OSS-120B」を動かすことができるという点です。
しかも「CUDA Toolkit」+「Python」+「PyTorch」の導入は非常に簡単です。

NVIDIAには頼らん!「TheRockのビルド」や「llama.cppのビルド」は自前でできる!という方は「AOOSTAR GEM12:7万円」+「メモリ128GB:4万円」の約11万円で「GPT-OSS-120B」を動かす環境を整えることができたことになります。
LM Studioをセットアップ

LM Studio ホームページより、「LM Studio」のソフトウェアをダウンロードします。
「LM Studio」をインストールします。

「LM Studio」のインストールは簡単です。

「LM Studio」で「GPT-OSS-120B」を動かしてみる!!
それでは「LM Studio」を実行してみましょう!!

「Choose your level」は取り敢えず「Power User」にしてみました。

「LM Studio」の最初の画面です。

画面左側にある虫眼鏡のアイコンをクリックすると「LLMモデル」をダウンロードするウインドウが出てきました。

「OpenAI gpt-oss-120b」が表示されているところをクリックします。
ダウンロードする「GPT-OSS-120B」のデータ容量は「63.39GB」もあります。

ダウンロード完了するまで待ちます・・・

待つこと十数分、やっと「GPT-OSS-120B」のダウンロードが完了しました!!

「GPT-OSS-120B」のモデルを読み込みます。

さっそく「GPT-OSS-120B」に質問してみましょう!
『あなたはだれですか?』
AI初心者丸出しですね・・・

しっかり質問に答えてくれました!!
簡単な質問なので、スピードは13.43tok/secとまずまずです。
次に少し高度な質問をしてみます。

なんか凄いですね!
表にしてPCメモリの高騰について説明してくれます。

今年6月頃からのDDR4メモリ製造中止や、最近のメモリ高騰などの情報が見当たりません。
「GPT-OSS-120B」はネットから切り離されたクローズドLLMを想定して開発されているため、このままの状態では2024年辺りまでの情報からの推測になっています。
最近の情報を取得してAI推論するには別途設定が必要なようです。
また、少し高度な質問だったためかスピードは7.92tok/secしか出ませんでした・・・
速度は速くないですが、個人のPCでこのようなAIとのやりとりが自由にできるのは感動です!!
PCパーツの負荷はどうなっている?
「GPT-OSS-120B」を動かしている際の、各PCパーツの負荷はどうなっているのでしょうか?

AI推論をGPUではなく、CPUで行っているためCPU使用率が高めです。
PCメモリは「GPT-OSS-120B」を読み込んだ時点で86GB付近まで使用率が上がりました。
このミニPCは現在「RAMdisk」を設定しており、PCメモリから16GB使用しているため(16GB分のRAM使用率はRAMdiskのものと考えられる)、実際には「GPT-OSS-120B」の展開に65~70GB程度使用していることになります。
GPUの「RTX4060ti 16GB」も頑張って働いています!!
まとめ
今回はAI用途としては非力な「Ryzen7 8845HS」搭載ミニPCを用いて「GPT-OSS-120B」が動くか試してみました。
「GPT-OSS-120B」では簡単な質問であれば13tok/sec程度のスピードが出ました。
すこし高度な質問をすると7~8tok/sec程度しかスピードが出ませんでした。
実際にローカルLLMに触れてみて、実用的に使用するとなるとできれば「20tok/sec」以上のスピードは欲しいと感じました。
しかし、『「GPT-OSS-120B」の運用についての練習と考えれば、面白いおもちゃにはなったな』とは思いました。
今後も様々なAIサービスが出現してくると予想される情勢のなか、今からでもローカルLLMなどのAI技術に触れておくのは非常に有用なことだと思います。
2026.4.30追記
グラフィックカードを強化して「Gemma4 31B」を動かしてみました!!

皆さんも良いPCライフを送ってくださいね!!
こちらの記事も合わせて読んでね!











コメント